Archive
It’s OK to Get Stressed Out with OpenAM
In fact, it’s HIGHLY recommended….
Performance testing and stress testing are closely related and are essential tasks in any OpenAM deployment.

When conducting performance testing, you are trying to determine how well your system performs when subjected to a particular load. A primary goal of performance testing is to determine whether the system that you just built can support your client base (as defined by your performance requirements). Oftentimes you must tweak things (memory, configuration settings, hardware) in order to meet your performance requirements, but without executing performance tests, you will never know if you can support your clients until you are actually under fire (and by then, it may be too late).
Performance testing is an iterative process as shown in the following diagram:

Each of the states may be described as follows:
- Test – throw a load at your server
- Measure – take note of the results
- Compare – compare your results to those desired
- Tweak – modify the system to help achieve your performance results
During performance testing you may continue in this loop until such time that you meet your performance requirements – or until you find that your requirements were unrealistic in the first place.
Stress testing (aka “torture testing”) goes beyond normal performance testing in that the load you place on the system intentionally exceeds the anticipated capacity. The goal of stress testing is to determine the breaking point of the system and observe the behavior when the system fails.

Stress testing allows you to create contingency plans for those ‘worse case scenarios’ that will eventually occur (thanks to Mr. Murphy).
Before placing OpenAM into production you should test to see if your implementation meets your current performance requirements (concurrent sessions, authentications per second, etc.) and have a pretty good idea of where your limitations are. The problem is that an OpenAM deployment is comprised of multiple servers – each that may need to be tested (and tuned) separately. So how do you know where to start?
When executing performance and stress tests in OpenAM, there are three areas where I like to place my focus: 1) the protected application, 2) the OpenAM server, and 3) the data store(s). Testing the system as a whole may not provide enough information to determine where problems may lie and so I prefer to take an incremental approach that tests each component in sequence. I start with the data stores (authentication and user profile databases) and work my way back towards the protected application – with each iteration adding a new component.

Note: It should go without saying that the testing environment should mimic your production environment as closely as possible. Any deviation may cause your test results to be skewed and provide inaccurate data.
Data Store(s)
An OpenAM deployment may consist of multiple data stores – those that are used for authentication (Active Directory, OpenDJ, Radius Server, etc.) and those that are used to build a user’s profile (LDAP and RDBMS). Both of these are core to an OpenAM deployment and while they are typically the easiest to test, a misconfiguration here may have a pretty big impact on overall performance. As such, I start my testing at the database layer and focus only on that component.

Performance of an authentication database can be measured by the average number of authentications that occur over a particular period of time (seconds, minutes, hours) and the easiest way to test these types of databases is to simply perform authentication operations against them.
You can write your own scripts to accomplish this, but there are many freely available tools that can be used as well. One tool that I have used in the past is the SLAMD Distributed Load Generation Engine. SLAMD was designed to test directory server performance, but it can be used to test web applications as well. Unfortunately, SLAMD is no longer being actively developed, but you can still download a copy from http://dl.thezonemanager.com/slamd/.
A tool that I have started using to test authentications against an LDAP server is authrate, which is included in ForgeRock’s OpenDJ LDAP Toolkit. Authrate allows you to stress the server and display some really nice statistics while doing so. The authrate command line tool measures bind throughput and response times and is perfect for testing all sorts of LDAP authentication databases.
Performance of a user profile database is typically measured in search performance against that database. If your user profile database can be searched using LDAP (i.e. Active Directory or any LDAPv3 server), then you can use searchrate – also included in the OpenDJ LDAP Toolkit. searchrate is a command line tool that measures search throughput and response time.
The following is sample output from the searchrate command:
------------------------------------------------------------------------------- Throughput Response Time (ops/second) (milliseconds) recent average recent average 99.9% 99.99% 99.999% err/sec Entries/Srch ------------------------------------------------------------------------------- 188.7 188.7 3.214 3.214 306.364 306.364 306.364 0.0 0.0 223.1 205.9 2.508 2.831 27.805 306.364 306.364 0.0 0.0 245.7 219.2 2.273 2.622 20.374 306.364 306.364 0.0 0.0 238.7 224.1 2.144 2.495 27.805 306.364 306.364 0.0 0.0 287.9 236.8 1.972 2.368 32.656 306.364 306.364 0.0 0.0 335.0 253.4 1.657 2.208 32.656 306.364 306.364 0.0 0.0 358.7 268.4 1.532 2.080 30.827 306.364 306.364 0.0 0.0
The first two columns represent the throughput (number of operations per second) observed in the server. The first column contains the most recent value and the second column contains the average throughput since the test was initiated (i.e. the average of all values contained in column one).
The remaining columns represent response times with the third column being the most recent response time and the fourth column containing the average response time since the test was initiated. Columns five, six, and seven (represented by percentile headers) demonstrate how many operations fell within that range.
For instance, by the time we are at the 7th row, 99.9% of the operations are completed in 30.827 ms (5th column, 7th row), 99.99% are completed in 306.364 ms (6th column, 7th row), and 99.999% of them are completed within 306.364 ms (7th column, 7th row). The percentile rankings provide a good indication of the real system performance and can be interpreted as follows:
- 1 out of 1,000 search requests is exceeding 30 ms
- 1 one out of 100,000 requests is exceeding 306 ms
Note: The values contained in this search were performed on an untuned, limited resource test system. Results will vary depending on the amount of JVM memory, the system CPU(s), and the data contained in the directory. Generally, OpenDJ systems can achieve much better performance that the values shown above.
There are several factors that may need to be considered when tuning authentication and user profile databases. For instance, if you are using OpenDJ for your database you may need to modify your database cache, the number of worker threads, or even how indexing is configured in the server. If your constraint is operating system based, you may need to increase the size of the JVM or the number of file descriptors. If the hardware is the limiting factor, you may need to increase RAM, use high speed disks, or even faster network interfaces. No matter what the constraint, you should optimize the databases (and database servers) before moving up the stack to the OpenAM instance.
OpenAM Instance + Data Store(s)
Once you have optimized any data store(s) you can now begin testing directly against OpenAM as it is configured against those data store(s). Previous testing established a performance baseline and any degradation introduced at this point will be due to OpenAM or the environment (operating system, Java container) where it has been configured.

But how can you test an OpenAM instance without introducing the application that it is protecting? One way is to generate a series of authentications and authorizations using direct interfaces such as the OpenAM API or REST calls. I prefer to use REST calls as this is the easiest to implement.
There are browser based applications such as Postman that are great for functional testing, but these are not easily scriptable. As such, I lean towards a shell or Perl script containing a loop of cURL commands.
Note: You should use the same authentication and search operations in your cURL commands to be sure that you are making a fair comparison between the standalone database testing and the introduction of OpenAM.
You should expect some decrease in performance when the OpenAM server is introduced, but it should not be too drastic. If you find that it falls outside of your requirements, however, then you should consider updating OpenAM in one of the following areas:
- LDAP Configuration Settings (i.e. connections to the Configuration Server)
- Session Settings (if you are hitting limitations)
- JVM Settings (pay particular attention to garbage collection)
- Cache Settings (size and time to live)
Details behind each of these areas can be found in the OpenAM Administration Guide.
You may also find that OpenAM’s interaction with the database(s) introduces searches (or other operations) that you did not previously test for. This may require you to update your database(s) to account for this and restart your performance testing.
Note: Another tool I have started playing with is the Java Application Monitor (aka JAMon). While this tool is typically used to monitor a Java application, it provides some useful information to help determine bottlenecks working with databases, file IO, and garbage collection.
Application + OpenAM Instance + Data Store(s)
Once you feel comfortable with the performance delivered by OpenAM and its associated data store(s), it is time to introduce the final component – the protected application, itself.
This will differ quite a bit based on how you are protecting your application (for instance, policy agents will behave differently from OAuth2/OpenID Connect or SAML2) but this does provide you with the information you need to determine if you can meet your performance requirements in a production deployment.
If you have optimized everything up to this point, then the combination of all three components will provide a full end to end test of the entire system. In this case, then an impact due to network latency will be the most likely factor in performance testing.
To perform a full end to end test of all components, I prefer to use Apache JMeter. You configure JMeter to use a predefined set of credentials, authenticate to the protected resource, and look for specific responses from the server. Once you see those responses, JMeter will act according to how you have preconfigured it to act. This tool allows you to generate a load against OpenAM from login to logout and anything in between.
Other Considerations
Keep in mind that any time that you introduce a monitoring tool into a testing environment, the tool (itself) can impact performance. So while the numbers you receive are useful, they are not altogether acurate. There may be some slight performance degradation (due to the introduction of the tool) that your users will never see.
You should also be aware that the client machine (where the load generation tools are installed) may become a bottleneck if you are not careful. You should consider distributing your performance testing tools across multiple client machines to minimize this effect. This is another way of ensuring that the client environment does not become the limiting factor.
Summary
Like many other areas in our field, performance testing an OpenAM deployment may be considered as much of an art as it is a science. There may be as many methods for testing as there are consultants and each varies based on the tools they use. The information contained here is just one approach performance testing – one that I have used successfully in our deployments.
What methods have you used? Feel free to share in the comments, below.
Understanding the iPlanetDirectoryPro Cookie
So you have run into problems with OpenAM and you are now looking at the interaction between the Browser and the OpenAM server. To assist you in your efforts you are using a plug-in like LiveHttpHeaders, SAML Tracer, or Fiddler and while you are intently studying “the dance” (as I like to call it), you come across a cookie called iPlanetDirectoryPro that contains a value that looks like something your two year old child randomly typed on the keyboard.
AQIC5wM2LY4Sfcy954IRN6Ixz7ZMwVdJkGlqr9urGirFNMQ.*AAJTSQACMDMAAlNLAAoxODIyMjQ4MDI0AAJTMQACMDI.*;
So what is this cookie and what do its contents actually mean?
I’m glad that you asked. Allow me to explain.
OpenAM Sessions
When a user successfully authenticates against an OpenAM server, a session is generated on that server. The session is nothing more than an object stored in the memory of the OpenAM server where it was created. The session contains information about the interaction between the client and the server. In addition to other things, the session will contain a session identifier, session times, the method used by the user to authenticate, and the user’s identity. The following is a snippet of the information contained in a user’s OpenAM session.
sessionID: AQIC5wM…
maxSessionTime: 120
maxIdleTime: 30
timeLeft: 6500
userID: bnelson
authLevel: 1
loginURL:/auth/UI/Login
service: ldapService
locale: en_US
Sessions are identified using a unique token called SSOTokenID. This token contains the information necessary to locate the session on the server where it is currently being maintained. The entire value of the iPlanetDirectoryPro cookie is the SSOTokenID.
SSOTokenID = AQIC5wM2LY4Sfcy954IRN6Ixz7ZMwVdJkGlqr9urGirFNMQ.*AAJTSQACMDMAAlNLAAoxODIyMjQ4MDI0AAJTMQACMDI.*;
While this may look like gibberish, it actually has meaning (and is actually quite useful).
The period (.) in the middle of the SSOTokenID is a delimiter that separates the SSOToken from the Session Key.
![]()
The SSOToken is a C66Encoded string that points to the session in memory. The Session Key is a Base64 Encoded string that identifies the location of the site and server where the session is being maintained. Additionally, the Session Key contains the storage key of the session should you need to identify it in a persistent storage location (such as the amsessiondb [OpenAM v10.0 or lower] or the OpenDJ CTS Store [OpenAM v10.1 or higher]).
So separating the SSOTokenID into its two components you will find the following:
SSOToken: AQIC5wM2LY4Sfcy954IRN6Ixz7ZMwVdJkGlqr9urGirFNMQ
Session Key: *AAJTSQACMDMAAlNLAAoxODIyMjQ4MDI0AAJTMQACMDI.*;
As previously indicated, the Session Key is a Base64 Encoded value. That means that you can decode the Session Key into meaningful information using Base64 Decoders.
| Note: A useful site for this is http://www.base64decode.org/. |
Running the Session Key listed above through a Base64 decoder yields the following
SI03SK1822248024S102
And can be broken down as follows:
Site: SI03
Server: S102
Storage Key: SK1822248024
| Note: The session key is a Base64 encoded Java DataInputStream. As such, the decoded data includes a combination of both discernible and non-discernible data. The output of running the session key through a Base64 decoder is similar to performing a UNIX ‘strings’ command on a binary database. The good thing is that the key bits of data are discernible (as shown above). |
This information tells you that the session identified by the SSOToken (AQIC5wM2LY4Sfcy954IRN6Ixz7ZMwVdJkGlqr9urGirFNMQ) is being maintained on server 02 in site 03 and is being persisted to the database and may be identified by storage key 1822248024.
| IMPORTANT:The SI and S1 keys have different meanings depending on whether the server belongs to a site or not. If the server belongs to a site, then SI contains the primary site’s ID and S1 contains the server’s ID. This is shown in the example, above. If the server does not belong to a site, then SI contains the server’s ID.
Since 10.1.0-Xpress the Storage Key is always part of the session ID. |
This may be useful information for debugging, but it is essential information for OpenAM – especially in cases where a load balancer may be configured incorrectly.
Session Stickiness
Another important cookie in OpenAM is amlbcookie. This cookie defines the server where the session is being maintained (i.e. amlbcookie=02) and should be used by load balancers to maintain client stickiness with that server. When used properly, the amlbcookie allows a client to be directed to the server where the session is available. If, however, a client ends up being sent to a different server (due to an incorrectly configured load balancer or the primary server being down) then the new OpenAM server can simply look at the information contained in the Session Key to determine the session’s location and request the session from that server.
| Note: Obtaining the session from another properly working OpenAM server is referred to as “cross talk” and should be avoided if at all possible. The additional overhead placed on both the OpenAM servers and the network can reduce overall performance and can be avoided by simply configuring the load balancer properly. |
Cross Talk Example
If Server 02 in Site 03 is maintaining the session and the client is sent to Server 01, then Server 01 can query Server 02 and ask for the session identified by the SSOToken value. Server 02 would send the session information to Server 01 where the request can now be serviced. If Server 01 needs to update any session information , then it does so by updating the session stored on Server 02. As long as Server 02 remains available, the session is maintained on that server and as such, the communication between Server 01 and Server 02 can become quite “chatty”.
Session Failover Example
If Server 02 in Site 03 is maintaining the session and the client is sent to Server 01, then Server 01 can query Server 02 and ask for the session identified by the SSOToken value. If Server 02 is offline (or doesn’t respond), then Server 01 can obtain the session from the session store (amsessiondb or OpenDJ CTS) using the Storage Key value.
| Note: Session persistence is not enabled by default. |
So now you know and you can stop blaming your two year old child.
How to Configure OpenAM Signing Keys
The exchange of SAML assertions between an Identity Provider (IdP) and a Service Provider (SP) uses Public-key Cryptography to validate the identity of the IdP and the integrity of the assertion.
Securing SAML Assertions
SAML assertions passed over the public Internet will include a digital signature signed by an Identity Provider’s private key. Additionally, the assertion will include the IdP’s public key contained in the body of a digital certificate. Service Providers receiving the assertion can be assured that it has not been tampered with by comparing the unencrypted (hashed) message obtained from the digital signature with a hashed version of the message created by the Service Provider using the same hashing algorithm.
The process can be demonstrated by the following diagram where the Signing process is performed by the IdP and the Verification process is performed by the SP. The “Data” referred to in the diagram is the assertion and the “Hash function” is the hashing algorithm used by both the Identity Provider and the Service Provider.
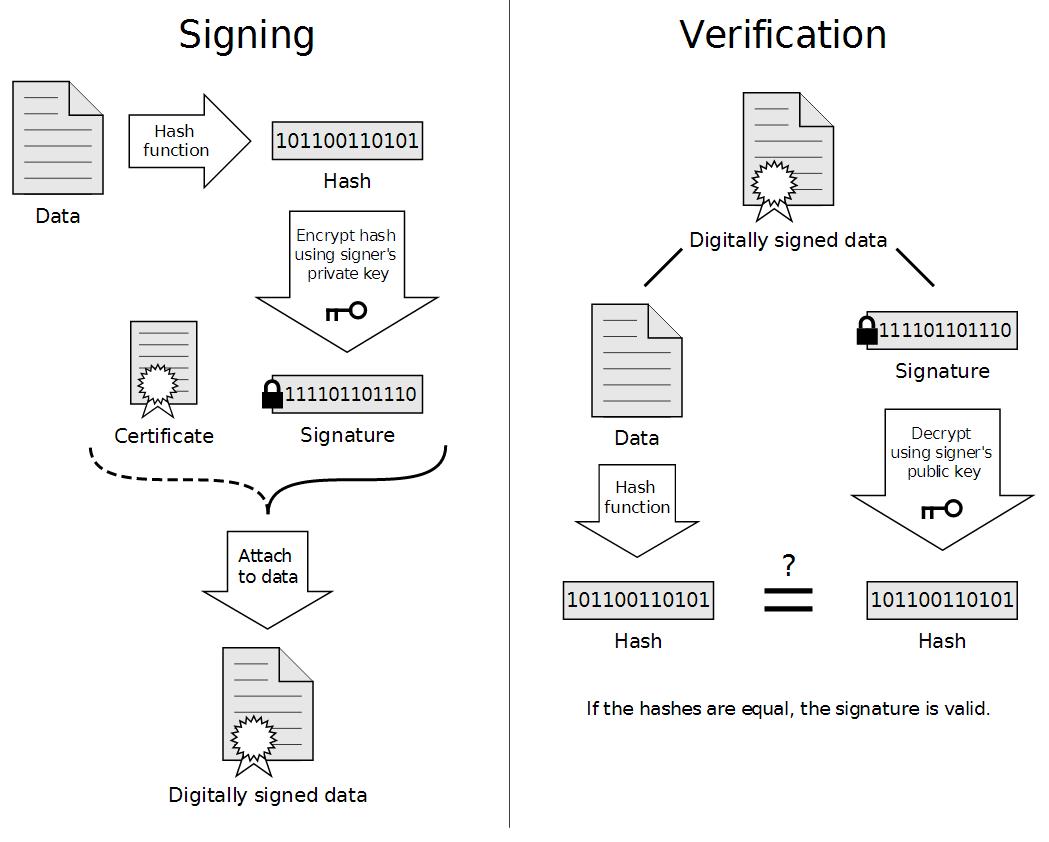
In order for an Identity Provider to sign the assertion, they must first have a digital certificate.
OpenAM includes a default certificate that can use for testing purposes. This certificate is common to all installations and while convenient, should not be used for production deployments. Instead, you should either use a certificate obtained from a trusted certificate authority (such as Thawte or Entrust) or generate your own self-signed certificate.
Note: For the purposes of this article, $CONFIG refers to the location of the configuration folder specified during the installation process. $URI refers to the URI of the OpenAM application; also specified during the installation process (i.e. /openam).
OpenAM’s Default Signing Key
OpenAM stores its certificates in a Java Keystore file located in the $CONFIG/$URI folder by default. This can be found in the OpenAM Console as follows:
- Log in to the OpenAM Console as the administrative user.
- Select the Configuration tab.
- Select the Servers and Sites subtab.
- In the Servers panel, select the link for the appropriate server instance.
- Select the Security tab.
- Select the Key Store link at the top of the page.
You will see that the default location for the Java Keystore file, all passwords, and the alias of the default test certificate as follows:

Viewing the Contents of OpenAM’s Default Certificate
You can view the contents of this file as follows:
- Change to the $CONFIG/$URI folder.
- Use the Java keytool utility to view the contents of the file. (Note: The contents of the file are password protected. The default password is: changeit)
# keytool –list –keystore keystore.jks
Enter keystore password: changeit
Keystore type: JKS
Keystore provider: SUN
Your keystore contains 1 entry
Alias name: test
Creation date: Jul 16, 2008
Entry type: PrivateKeyEntry
Certificate chain length: 1
Certificate[1]:
Owner: CN=test, OU=OpenSSO, O=Sun, L=Santa Clara, ST=California, C=US
Issuer: CN=test, OU=OpenSSO, O=Sun, L=Santa Clara, ST=California, C=US
Serial number: 478d074b
Valid from: Tue Jan 15 19:19:39 UTC 2008 until: Fri Jan 12 19:19:39 UTC 2018
Certificate fingerprints:
MD5: 8D:89:26:BA:5C:04:D8:CC:D0:1B:85:50:2E:38:14:EF
SHA1: DE:F1:8D:BE:D5:47:CD:F3:D5:2B:62:7F:41:63:7C:44:30:45:FE:33
SHA256: 39:DD:8A:4B:0F:47:4A:15:CD:EF:7A:41:C5:98:A2:10:FA:90:5F:4B:8F:F4:08:04:CE:A5:52:9F:47:E7:CF:29
Signature algorithm name: MD5withRSA
Version: 1
*******************************************
*******************************************
Replacing OpenAM’s Default Keystore
You should replace this file with a Java Keystore file containing your own key pair and certificate. This will be used as the key for digitally signing assertions as OpenAM plays the role of a Hosted Identity Provider. The process for performing this includes five basic steps:
- Generate a new Java Keystore file containing a new key pair consisting of the public and private keys.
- Export the digital certificate from the file and make it trusted by your Java installation.
- Generate encrypted password files that permit OpenAM to read the keys from the Java Keystore.
- Replace OpenAM’s default Java Keystore and password files with your newly created files.
- Restart OpenAM.
The following provides the detailed steps for replacing the default Java Keystore.
1. Generate a New Java Keystore Containing the Key Pair
a) Change to a temporary folder where you will generate your files.
# cd /tmp
b) Use the Java keytool utility to generate a new key pair that will be used as the signing key for your Hosted Identity Provider.
# keytool -genkeypair -alias idfsigningkey -keyalg RSA -keysize 1024 -validity 730 -storetype JKS -keystore keystore.jks
Enter keystore password: cangetin
Re-enter new password: cangetin
What is your first and last name?
[Unknown]: idp.identityfusion.com
What is the name of your organizational unit?
[Unknown]: Security
What is the name of your organization?
[Unknown]: Identity Fusion
What is the name of your City or Locality?
[Unknown]: Tampa
What is the name of your State or Province?
[Unknown]: FL
What is the two-letter country code for this unit?
[Unknown]: US
Is CN=idp.identityfusion.com, OU=Security, O=Identity Fusion, L=Tampa, ST=FL, C=US correct?
[no]: yes
Enter key password for <signingKey>
(RETURN if same as keystore password): cangetin
Re-enter new password: cangetin
You have now generated a self-signed certificate but since it has been signed by you, it is not automatically trusted by other applications. In order to trust the new certificate, you need to export it from your keystore file, and import it into the cacerts file for your Java installation. To accomplish this, perform the following steps:
2. Make the Certificate Trusted
a) Export the self-signed certificate as follows:
# keytool -exportcert -alias idfsigningkey -file idfSelfSignedCert.crt -keystore keystore.jks
Enter keystore password: cangetin
Certificate stored in file <idfSelfSignedCert.crt>
b) Import the certificate into the Java trust store as follows:
# keytool -importcert -alias idfsigningkey -file idfSelfSignedCert.crt -trustcacerts -keystore /usr/lib/jvm/java-7-oracle/jre/lib/security/cacerts
Enter keystore password: changeit
Owner: CN=idp.identityfusion.com, OU=Security, O=Identity Fusion, L=Tampa, ST=FL, C=US
Issuer: CN=idp.identityfusion.com, OU=Security, O=Identity Fusion, L=Tampa, ST=FL, C=US
Serial number: 34113557
Valid from: Thu Jan 30 04:25:51 UTC 2014 until: Sat Jan 30 04:25:51 UTC 2016
Certificate fingerprints:
MD5: AA:F3:60:D1:BA:1D:C6:64:61:7A:CC:16:5E:1C:12:1E
SHA1: 4A:C3:7D:0E:4C:D6:4C:0F:0B:6B:EC:15:5A:5B:5E:EE:BB:6A:A5:08
SHA256: A8:22:BE:79:72:52:02:6C:30:6E:86:35:DA:FD:E0:45:6A:85:2C:FE:AA:FB:69:EA:87:30:65:AF:2E:65:FB:EB
Signature algorithm name: SHA256withRSA
Version: 3
Extensions:
#1: ObjectId: 2.5.29.14 Criticality=false
SubjectKeyIdentifier [
KeyIdentifier [
0000: 12 3B 83 BE 46 D6 D5 17 0F 49 37 E4 61 CC 89 BE .;..F….I7.a…
0010: 6D B0 5B F5 m.[.
]
]
Trust this certificate? [no]: yes
OpenAM needs to be able to open the truststore (keystore.jks) and read the key created in step 1. The private key and truststore database have both been locked with a password that you entered while configuring the truststore and signing key, however. For OpenAM to be able to read this information you need to place these passwords in files on the file system.
3. Generate Encrypted Password Files
Note: The passwords will start out as clear text at first, but will be encrypted to provide secure access.
a) Create the password file for the trust store as follows:
# echo “cangetin” > storepass.cleartext
b) Create the password file for the signing key as follows:
# echo “cangetin” > keypass.cleartext
c) Prepare encrypted versions of these passwords by using the OpenAM ampassword utility (which is part of the OpenAM administration tools).
# ampassword –encrypt keypass.cleartext > .keypass
# ampassword –encrypt storepass.cleartext > .storepass
Note: Use these file names as you will be replacing the default files of the same name.
4. Replace the Default OpenAM Files With Your New Files
a) Make a backup copy of your existing keystore and password files.
# cp $CONFIG/$URI/.keypass $CONFIG/$URI/.keypass.save
# cp $CONFIG/$URI/.storepass $CONFIG/$URI/.storepass.save
# cp $CONFIG/$URI/keystore.jks $CONFIG/$URI/keystore.jks.save
b) Overwrite the existing keystore and password files as follows:
# cp .keypass $CONFIG/$URI/.keypass
# cp .storepass $CONFIG/$URI/.storepass
# cp keystore.jks $CONFIG/$URI/keystore.jks
5. Restart the container where OpenAM is currently running.
This will allow OpenAM to use the new keystore and read the new password files.
Verifying Your Changes
You can use the keytool utility to view the contents of your Keystore as previously mentioned in this article. Alternately, you can log in to the OpenAM Console and see that OpenAM is using the new signing key as follows:
- Log in to OpenAM Console.
- Select the Common Tasks tab.
- Select the Create Hosted Identity Provider option beneath the Create SAMLv2 Providers section.
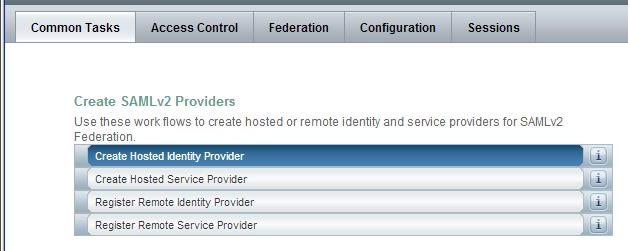
Verify that you now see your new signing key appear beneath the Signing Key option as follows:
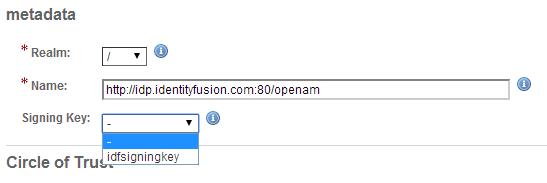
You have now successfully replaced the default OpenAM Java Keystore with your own custom version.
Single Sign-On Explained
So what is SSO and why do I care?
SSO is an acronym for “Single Sign-On”. There are various forms of single sign-on with the most common being Enterprise Single Sign-On (ESSO) and Web Single Sign-On (WSSO).
Each method utilizes different technologies to reduce the number of times a user has to enter their username/password in order to gain access to protected resources.
Note: There are various offshoots from WSSO implementations – most notably utilizing proxies or portal servers to act as a central point of authentication and authorization.
Enterprise Single Sign-On
In ESSO deployments, software typically resides on the user’s desktop; the desktop is most commonly Microsoft. The software detects when a user launches an application that contains the username and password fields. The software “grabs” a previously saved username/password from either a local file or remote storage (i.e. a special entry in Active Directory), enters these values into the username and password fields on behalf of the application, and submits the form on behalf of the user. This process is followed for every new application that is launched that contains a username and password field. It can be used for fat clients (i.e. Microsoft Outlook), thin clients (i.e. Citrix), or Web-based applications (i.e. Web Forms) and in most cases the applications themselves are not even aware that the organization has implemented an ESSO solution. There are definite advantages to implementing an ESSO solution in terms of flexibility. The drawback to ESSO solutions, however, is that software needs to be distributed, installed, and maintained on each desktop where applications are launched. Additionally, because the software resides on the desktop, there is no central location in which to determine if the user is allowed access to the application (authorization or AuthZ). As such, each application must maintain its own set of security policies.
The following diagram provides an overview of the steps performed in ESSO environments.

A user launches an application on their desktop. An agent running in the background detects a login screen from a previously defined template. If this is the first time the user has attempted to access this application, they are prompted to provide their credentials. Once a successful login has been performed, the credentials are stored in a credentials database. This database can be a locally encrypted database or a remote server (such as Active Directory). Subsequent login attempts do not prompt the user for their credentials. Instead, the data is simply retrieved from the credentials database and submitted on behalf of the user.
Container-Based Single Sign-On
Session information (such as authenticated credentials) can be shared between Web applications deployed to the same application server. This is single sign-on in its most basic and limited fashion as it can only be used across applications in the same container.
The following diagram provides a high level overview of the steps performed in container-based single sign-on environments.

A user accesses a Web application through a standard Web browser. They are prompted for their credentials which can be basic (such as username and password) or can utilize other forms of authentication (such as multi-factor, X.509 certificates, or biometric). Once the user has authenticated to the application server, they are able to access other applications installed in the same J2EE container without having to re-authenticate (that is, if the other applications have been configured to permit this).
Traditional Web Single Sign-On
In contrast, WSSO deployments only apply to the Web environment and Web-based applications. They do not work with fat clients or thin clients. Software is not installed on the user’s desktop, but instead resides centrally within the Web container or J2EE container of the Web application being protected. The software is often times called a “policy agent” and its purpose is to manage both authentication and authorization tasks.
The following diagram provides a high level overview of traditional Web Single Sign-On.

A user first attempts to access a Web resource (such as ADP) through a Web browser. They are not authenticated to the domain so they are directed to the central authentication server where they provide their credentials. Once validated, they receive a cookie indicating that they are authenticated to the domain. They are then redirected back to the original Web resource where they present the cookie. The Web resource consults the authentication server to determine if the cookie is valid and that the session is still active. They also determine if this user is allowed access to the Web resource. If so, they are granted access. If the user were to attempt to access another Web resource in the same domain (i.e. Oracle eBusiness Suite), they would present the cookie as proof that they are authenticated to the domain. The Web resource consults the authentication server to determine the validity of the cookie, session, and access rights. This process continues for any server in the domain that is protected by WSSO.
Portal or Proxy-Based Single Sign-On
Portal and proxy-based single sign-on solutions are similar to Standard Web Single Sign-On except that all traffic is directed through the central server.
Portal Based Single Sign-On
Target-based policy agents can be avoided by using Portal Servers such as LifeRay or SharePoint. In such cases the policy agent is installed in the Portal Server. In turn, the Portal Server acts as a proxy for the target applications and may use technologies such as SAML or auto-form submission. Portal Servers may be customized to dynamically provide access to target systems based on various factors. This includes the user’s role or group, originating IP address, time of day, etc. Portal-based single sign-on (PSSO) serves as the foundation for most vendors who are providing cloud-based WSSO products. When implementing PSSO solutions, direct access to target systems is still permitted. This allows users to bypass the Portal but in so doing, they need to remember their application specific credentials. You can disallow direct access by creating container-specific rules that only allow traffic from the Portal to the application.
Single Sign-On Involving Proxy Servers
Proxy servers are similar to PSSO implementations in that they provide a central point of access. They differ, however, in that they do not provide a graphical user interface. Instead, users are directed to the proxy through various methods (i.e. DNS, load balancers, Portal Servers, etc.). Policy agents are installed in the proxy environment (which may be an appliance) and users are granted or denied access to target resources based on whether they have the appropriate credentials and permission for the target resource.
The following diagram provides a high level overview of centralized single sign-on using Portal or Proxy Servers.

Federation
Federation is designed to enable Single Sign-On and Single Logout between trusted partners across a heterogeneous environment (i.e. different domains). Companies that wish to offer services to their customers or employees enter into a federated agreement with trusted partners who in turn provide the services themselves. Federation enables this partnership by defining a set of open protocols that are used between partners to communicate identity information within a Circle of Trust. Protocols include SAML, Liberty ID-FF, and WS-Federation.
Implementation of federated environments requires coordination between each of its members. Companies have roles to play as some entities act as identity providers (IDP – where users authenticate and credentials are verified) and service providers (SP – where the content and/or service originate). Similar to standard Web Single Sign-On, an unauthenticated user attempting to access content on a SP is redirected to an appropriate IDP where their identity is verified. Once the user has successfully authenticated, the IDP creates an XML document called an assertion in which it asserts certain information about the user. The assertion can contain any information that the IDP wishes to share with the SP, but is typically limited to the context of the authentication. Assertions are presented to SPs but are not taken at face value. The manner in which assertions are validated vary between the type of federation being employed and may range from dereferencing artifacts (which are similar to cookies) or by verifying digital signatures associated with an IDP’s signed assertion.
The interaction between the entities involved in a federated environment (user, SP and IDP) is similar to the Web Single Sign-On environment except that authentication is permitted across different domains.
A major difference between federated and WSSO environments involves the type of information generated by the authenticating entity to vouch for the user and how it is determined that that vouch is valid and had not been altered in any way.
The following table provides a feature comparison between Web SSO and Enterprise SSO.
| Features | WSSO / PSSO / Proxy | ESSO |
| Applications Supported: | Web Only | Web Applications and Fat Clients |
| “Agent” Location: | Target System | User Desktop |
| Technologies: | SAML, Form Submission, Cookies | Form Submission |
| Internal Users? | Yes | Yes (through portal) |
| External Users? | Yes | No |
| Central Authentication? | Yes | No |
| Central Authorization? | Yes | No |
| Central Session Logoff? | Yes | No |
| Global Account Deactivation? | Yes (through password change) | No |
Opinions About the Federal Government’s Identity Initiative
Interesting read. This is essentially a WebSSO initiative with authentication based on CAC type ID cards or OpenID.
The CAC type of implementation (ID Cards) are not practical as they require everyone to have a card reader on their PC in order to do business with the government. I don’t see this happening anytime too soon.
I understand that there are several holes in the OpenID initiative. I wonder if they have been fixed (I wonder if it matters).
Either way, Sun’s openSSO initiative is well positioned as it allows OpenID as a form of authentication. The fact that the government is looking at open source for this (OpenID) bodes well for openSSO.
Link to article on PCmag.com:
http://blogs.pcmag.com/securitywatch/2009/09/federal_government_starts_iden.php.
Text version of the article:
Federal Government Starts Identity Initiative
As part of a general effort of the Obama administration to make government more accessible through the web, the Federal government, through the GSA (Government Services Administration), is working to standardize identity systems to hundreds of government web sites. The two technologies being considered are OpenID and Information Cards (InfoCards). The first government site to implement this plan will be the NIH (National Institutes of Health).
OpenID is a standard for “single sign-on”. You may have noticed an option on many web sites, typically blogs, to log on with an OpenID. This ID would be a URI such as john_smith.pip.verisignlabs.com, which would be John Smith’s identifier on VeriSign’s Personal Identity Portal. Many ISPs and other services, such as AOL and Yahoo!, provide OpenIDs for their users. When you log on with your OpenID the session redirects to the OpenID server, such as pip.verisignlabs.com. This server, called an identity provider, is where you are authenticated, potentially with stricter measures than just a password. VeriSign is planning to add 2-factor authentication for example. Once authenticated or not, the result is sent back to the service to which you were trying to log in, also known as a relying party.
Information Cards work differently. The user presents a digital identity to a relying party. This can be in a number of forms, from a username/password to an X.509 certificate. IDs can also be managed by service providers who can also customize their authentication rules.
The OpenID Foundation and Information Card Foundation have a white paper which describes the initiative. Users will be able to use a single identity to access a wide variety of government resources, but in a way which preserves their privacy. For instance, there will be provision for the identity providers to supply each government site with a different virtual identity managed by the identity provider, so that the user’s movements on different government sites cannot be correlated.
Part of the early idea of OpenID was that anyone could make an identity provider and that everyone will trust everyone else’s identity provider, but this was never going to work on a large scale. For the government there will be a white list of some sort that will consist of certified identity providers who meet certain standards for identity management, including privacy protection.
 |
